
nathanielbabiak 2022-04-08 03:49 (Edited)
This is a tool for compressing and decompressing ROM data up to 16 kB.
The tool uses the ROM comment to determine whether source ROM data is original or compressed. If the ROM comment is prefixed with *, it assumes compressed, otherwise it assumes original. It will update the comment when saving the file.
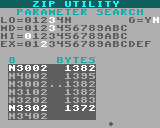
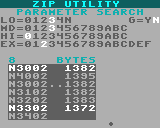
When compressing, there's a second screen of input, you get to pick the compression level and parameters. The level represents how much computation should be performed. Lower is less compression, but runs faster. The max. available level is proportional to the ROM size (it's not constant). Parameters can be automatically searched, or you can enter them manually.
When compressing, there's a third screen - the compression itself. The current best parameters are shown at the top in white. A dot across the bottom shows compression progress, and a dark rectangle window shows the set of parameters currently being evaluated. If search was selected, all reasonable sets of parameters will be evaluated. The number of sets that have been evaluated is shown in blue number to the left of BYTES. It ranges from 60 to 200, and usually takes around 120 or so. After finding the best parameters (or entering them manually), the file is encoded and saved.
Note the source and destination ROM can be the same. Before saving a compressed file, it will compare the original file's hash to the hash of a temporary unzipped copy, this will provide confidence that the file is de-compressible. It won't save if it detects a hash mismatch. (If you can develop ROM data that causes a hash mismatch PLEASE share the ROM data - I want this tool to work!)
The tool can perform decompression too. Or, the decompression code can execute at runtime within your own program. Just copy-paste the code at the top of the tool.
Enjoy!
nathanielbabiak 2022-04-08 04:48 (Edited)
Second upload is just a revised file name - it looks prettier in the LowRes NX tool menu.
The compressor runs an improved version of LZSS while still minimizing the number of tokens required to decompress. The improvements are:
The match search algorithm uses both a look-up table and and three-byte string elimination to make it as fast as possible, although I haven't actually optimized the tool's code line-by-line.
As far as cramming an algorithm of this complexity into LowRes NX, I must confess I've completely abused the array element capabilities of the system for data buffers. There are 8-bit arrays of 64k elements, 16-bit at 32k elements, 24-bit at 112k elements, and 32-bit at 16k elements. It's 528 kB total! Also, I originally planned to support ROM data up to 20 kB, so the value on line 15 ($4FFF) is just a mistake.
Much of the published tool is based on PuCrunch. But a few things I tried would've improved compression by small percentages, but it's not worthwhile because the max. file size is only 16 kB, so those percentages don't amount to anything compared to the cost paid in tokens/runtime:
I investigated Exomizer too, but it uses some pretty advanced techniques, and, while the decompressor is transferrable to LowRes NX, the compressor is not. It's really only designed to compress on modern hardware. It would work as a cross-platform compressor, but that's too much for most folks. But, while the compressor beats PuCrunch by a few percent, and mine by a fair bit, the decompressor is slower and requires a bunch more tokens than mine.
Multi-position deferred matching and single- and multi-position hasty matching were also tried (since I was kind'a bummed-out that I couldn't get PuCrunch's optimal matching to work faster). The benefit of these is minimal and increases the tool runtime linearly for each position evaluated.
Adaptive Rice encoding was considered, but it looked like it would add approximately 40 tokens and I really wanted to keep it around 350 total.
Encoding the match lengths within the header (rather than throughout the file) and compressing the (much larger) header recursively yielded some savings, but it wasn't worth the token cost.
I also tried a bit-wise bernoullizip on the match lengths within the header, but I couldn't get any savings unless the split was 70%-30% or more (most of my test files were 60%-40% at best).
I even tried associating unmatched bytes with a variable Elias Gamma length (rather than encoding them with the minimum length value) proportional to their frequency when compared to the frequency of matches of specific lengths. This became a chicken-and-egg problem, and would've required a second heuristic! It was also super slow.
Ultimately, I realized simpler-is-better, and this is the result.
GAMELEGEND 2022-04-08 04:51
I just took a glance at the code
just holy crap how long did this take?
nathanielbabiak 2022-04-08 05:02 (Edited)
I read the PuCrunch webpage some day in November of 2020, coded up a PuCrunch decompressor in two days on Dec. 2 and 3 of 2020, and then it's just sat for over two years. It popped back into my mind on March 1 of this year, here, where I realized it'd work. I picked it up again March 8 of this year, been working on it averaging 3.5 to 4 hours a day, five days a week since then.
So around 80 or 90 hours, excluding the days in 2020. This time includes my ROM hash tool though too - I wanted to develop that to easily check for file integrity within the toolchain. The hash function itself was developed a while back for my SCHIP interpreters. It also includes a bit of overlap with my work on Cybernoid.
McPepic 2022-04-08 14:25
This is awesome! This will save so much space for background data!
nathanielbabiak 2022-04-08 14:36 (Edited)
Yeah I had written some stuff a while ago that rendered background data pixel-by-pixel at runtime (the data was too large to save pre-rendered in ROM). It was super slow and used too many tokens. Figured the render could happen in a tool and then be compressed with this tool, with only decompression happening at runtime.
Honestly I created this because I thought the Cybernoid artwork was going to greatly exceed the allowable data limits, but apparently it's not necessary.
McPepic 2022-04-08 16:24
I honestly don’t know a lot about data compression besides what I learned about how Pokémon Red and Blue compress Pokémon sprite data, which was pretty interesting. There’s a YouTube channel that explains that has an interesting video on it called Retro Game Mechanics Explained.
nathanielbabiak 2022-04-08 21:01 (Edited)
I think I found the video - this one? The video explains some rather clever algorithms!
The algorithms are called RLE and Elias Gamma code, although it looks like the programmers made some tweaks to better suit the DMG's 8080/Z80 chip. There's one more algorithm/concept I missed the first time through the video - prefix escape codes. These are pretty well explained in PuCrunch's tagging system.
My upload uses LZSS, a more generalized/flexible version of RLE, and uses both Elias gamma code and Rice code, a more generalized/flexible version of Elias Gamma. It doesn't use prefix escape codes since it costs too much runtime/tokens.
And, as far as considering the Pokemon data as 'sparsely colored' - this compressor won't do that, it's general-purpose. That video does a great job though of explaining how to separate-out 2bpp graphics into two bit planes, group them in 2D space, and then encode them efficiently. I had wanted to explore low-resolution/low-colorspace 2D compression topic at some point - that video is an excellent starting point!
For sparsely colored image data, my gut feeling is that Nintendo's compressor will beat mine, and it would be comparably fast, and use a similar amount of tokens. I might investigate it in the future if this one isn't adequate for my needs.
-SkyLock24- 2022-04-14 02:28
Very interesting 🧐 👍🏻
{kind=link}
{kind=link}